SATELLITE RELOADED (reverse 250)
15.10.2014 10:12, by Dor1s
Event:
Description
Download this file and find the flag.
Solution
After unziping this file we found that it's x64 ELF. At the main function we see some buffer dexoring:
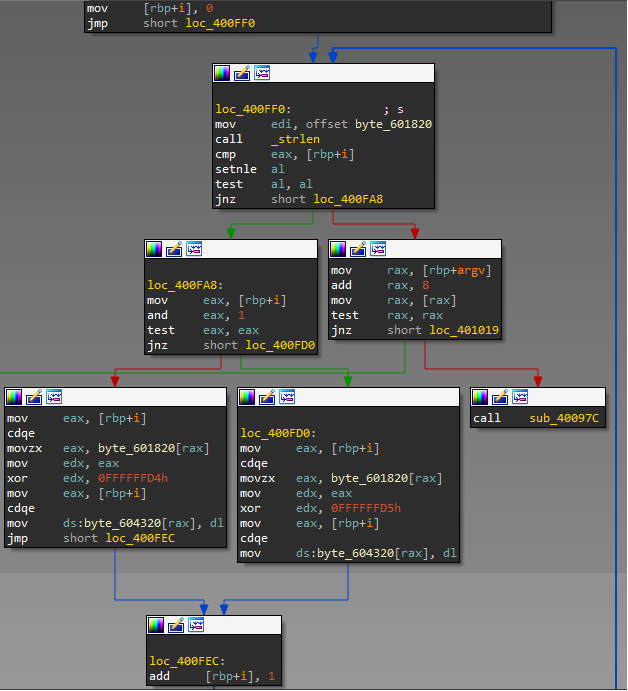
Lets dexor it and save to file (IDA command line with idapython used):